VASA-1 Microsoft
VASA-1とは
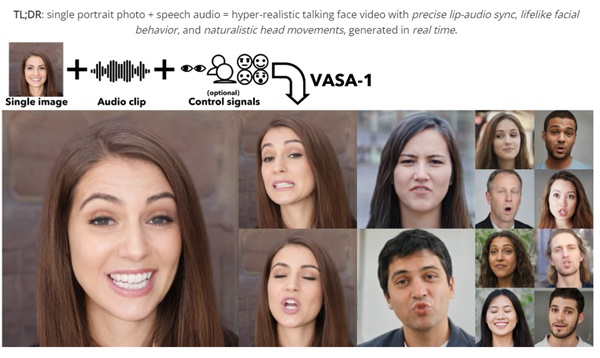
VASA-1は、Microsoftが開発した革新的なAIモデル。1枚の静止画像と音声クリップを入力するだけで、その画像の人物が実際に話しているかのように自然な表情や口の動きを再現した動画を生成することができます。
主な特徴
- 1枚の顔写真と音声クリップから、リアルタイムで高品質な話し手の動画を生成できる。
- 唇の動きと音声の完璧な同期だけでなく、表情の変化、視線の動き、頭の向きなど、自然な動きを再現する。
- 英語以外の言語や歌声の入力にも対応可能。
- 漫画のキャラクターや絵画の人物からも動画を生成できる。
StableDiffusionのImage2Imageをさらに進化させたようなものでしょうか。
動作原理
VASA-1は、大量の会話動画から学習したディープラーニングモデルです。顔の外観と動きを分離して認識し、入力された静止画像と音声から、リアルタイムで自然な動きを合成します。
なお、VASA-1 は研究のためのデモンストレーションであり、製品化やAPIの公開は計画していないとマイクロソフト自身が明記しています。
VASA-1の用途
VASA-1は、Microsoftが開発した革新的なAIモデルで、1枚の顔写真と音声ファイルから超リアルな話す顔のビデオを生成することができます。VASA-1の潜在的な用途は以下のようなものが考えられます。
エンターテインメント分野
- 亡くなった俳優を甦らせて新作映画に出演させる
- 新しい映画、TVシリーズ、ビデオゲームのキャラクターを作成する
- バーチャルインフルエンサーやYouTuberを生み出す
アクセシビリティ向上
- 音声合成と組み合わせて、視覚障害者のための音声ガイドを作成する
- 手話通訳者の代替として機能する
教育分野
- オンラインの講義やeラーニングコンテンツを充実させる
- 歴史上の人物を再現してわかりやすい教材を作成する
マーケティング・広告
- 企業のマスコットキャラクターをアニメーション化する
- 製品紹介やデモンストレーションビデオを作成する
その他
- バーチャル会議やプレゼンテーションでアバターを使用する
- 言語学習のための会話練習ツールとして活用する
VASA-1の悪用の懸念
VASA-1を悪用すれば、実在する人物になりすまして偽の動画(ディープフェイク)を簡単に作成できてしまう危険性があります。
そのため、マイクロソフトは現時点でVASA-1の一般公開や製品化は計画していません。
専門家からは、ディープフェイクによる偽情報拡散への懸念が指摘されています。生成AIの発展に伴い、悪用防止のための技術の向上も求められています。
soraなんかも、リアルすぎてディープフェイクに利用されるかも、って公開を遅らせているらしいですね。ヤバいくらいリアルなんだぞ、っていう宣伝とも思えなくもないですが…。
Microsoftは、VASA-1の研究成果を公開する一方で、悪用リスクを認識しています。この革新的技術が適切に活用されるよう、倫理的な側面での議論と対策が重要となります。
VASA-1のまとめ
- VASA-1は1枚の写真と音声クリップから、その人物が自然に話している動画を生成できる
- さまざまな用途が考えられる反面、ディープフェイクなどの悪用の懸念もあり
- Microsoftは、VASA-1はデモンストレーションであり製品化は考えていないとしている