
word2vecの学習済みモデル
日本語の学習済みword2vecモデルには以下のようなものがあります。
エンティティベクトル (WikiEntVec)
- Wikipediaのデータを使って学習
- 次元数は100, 200, 300の3種類
- 分かち書きにはmecab-ipadic-NEologdを使用
chiVe
- 国立国語研究所の日本語ウェブコーパス(NWJC)で学習
- 次元数は300
- 分かち書きにはSudachiを使用
fastText
- 多言語モデルの一部として日本語も含まれている
- 分かち書きにはmecabを使用(おそらくipadic辞書)
- 日本語Wikipedia全記事を対象に学習したモデル
- 次元数は160
これらのモデルは、学習に使用したデータやツール、分かち書きの方法などが異なります。特に日本語の場合は、分かち書きの前処理が重要で、使用する方法や辞書によってモデルの性能に大きな影響を与えます。
また、研究では自前でword2vecモデルを学習させ、既存モデルと比較することで、より良いモデルの作成方法を探ることもできます。例えば、日本語WordNetから名詞のみを抽出してskip-gramで学習させたモデルは、高い性能を示したという報告もあります。
エンティティベクトル (WikiEntVec)
chieVe
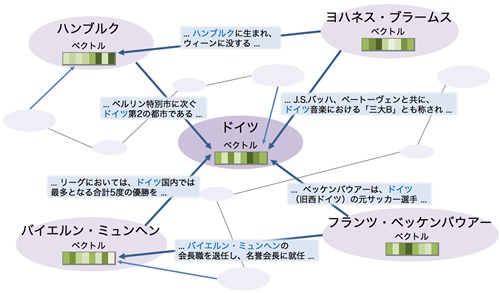
chiVe (チャイブ, Sudachi Vector) は、大規模コーパスと複数粒度分割に基づく日本語の単語分散表現 (word embedding) モデルです。
関連 WorksApplications/chiVe: Japanese word embedding with Sudachi and NWJC
主な特徴は以下の通りです。
- Word2Vec (gensim) の Skip-gram アルゴリズムを使用して学習されている
- 学習コーパスには国立国語研究所の日本語ウェブコーパス (NWJC) や CommonCrawl から取得したウェブページ文章を使用
- 形態素解析器 Sudachi を使用し、Sudachi で定義されている A/B/C の3つの分割単位でコーパスを解析した結果を元に学習
- 複数粒度の分割結果を全て学習に使うことで、より長い固有表現や複合語が、その構成語との類似度が高くなる
- 最大で約360万語の豊富な語彙数を持つモデルが利用可能
- 株式会社ワークスアプリケーションズにより開発・メンテナンスされており、実用性が高い
chiVeは、高品質でメンテナンスされた日本語の単語分散表現モデルとして、自然言語処理タスクでの利用が期待されています。例えば、chiVeを使うことで、GiNZAなどの形態素解析器の単語分散表現を置き換え、文書分類の精度向上などが見込めます。
日本語のモデルなので、word2vecとはどういうものか、触れてみるのに最適なモデルです。
関連 【Word2vecモデル生成・超入門編】gensim、ja.text8、chiVe(チャイブ)【Python】 #Python – Qiita
fastText
fastTextは、Word2vecの考案者であるミコロフ氏がFacebookに移籍後、2016年に開発したライブラリです。Word2vecの拡張版で、単語のベクトル化に加えて、部分文字列(n-gram)のベクトル化も行うことができます。これにより、学習データに含まれない未知の単語に対してもベクトル表現が可能になりました。
関連 fastText
Word2vecとfastTextは、自然言語処理の分野で広く使われている単語の分散表現手法です。
Word2vecは、Googleの研究者トマス・ミコロフ氏が2013年に提案した手法で、文章中の単語の前後関係から単語の意味を数値ベクトル化します。単語同士の意味的な関係性を計算できるようになり、自然言語処理の性能が大幅に向上しました。
Word2vecとfastTextの主な違いは以下の通りです
- 未知語への対応: fastTextは部分文字列のベクトル化により未知語にも対応できますが、Word2vecは学習データ内の単語しかベクトル化できません。
- 学習データ量: fastTextはWord2vecより少ないデータで高い精度が得られます。
- 計算コスト: fastTextの方がWord2vecよりも計算コストが低く、学習が高速です。
両手法とも、単語の意味的な関係性を利用した自然言語処理タスクに広く利用されています。例えば
- 単語の類似度計算・類義語抽出
- 単語ベクトル演算 (例: 王 男 + 女 = 女王)
- 文章の感情分析・カテゴリ分類
- 機械翻訳・対話システムなど
fastTextはWord2vecに比べて未知語にも対応できるため、より柔軟に様々な自然言語処理タスクに活用できます。
word2vecとは
Word2vecは、自然言語処理における単語の分散表現(単語の意味をベクトルで表現する手法)を獲得するための一連のモデル群です。
単語の意味をコンパクトなベクトルに変換し、言語をコンピュータで効率的に扱えるようにする画期的な手法と言えます。その登場により、自然言語処理は大きく発展しました。
主な特徴は以下の通りです。
- 単語をベクトル(数値の列)で表現することで、単語間の意味的な近さを定量化できる
- 周囲の単語から対象単語を予測する(またはその逆)ニューラルネットワークモデルを用いて、大規模コーパスから単語ベクトルを学習する
- Continuous Bag-of-Words (CBOW)とSkip-gramの2つのモデルアーキテクチャがある
CBOWは周囲の単語から中心単語を予測
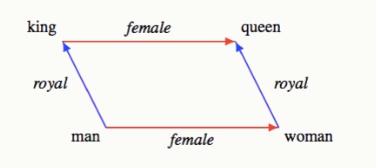
Skip-gramは中心単語から周囲の単語を予測 - 得られた単語ベクトルには単語の意味や文法の情報が反映され、ベクトル演算により単語間の関係性を捉えられる(例: king man + woman ≈ queen)
- 2013年にGoogleのTomas Mikolov氏らによって提案され、自然言語処理に大きなブレイクスルーをもたらした
- 比較的シンプルなモデルでありながら高い表現力を持ち、様々なタスクに応用可能
TensorFlowにもword2vecが実装されています。下記ページでは、Kerasのサブクラス化APIを使ってword2vecモデルを定義し、実装方法が具体的に説明されています。
関連 word2vec | Text | TensorFlow
word2vecの用途とは
word2vecを視覚化に使った主な実例をまとめると以下のようになります。
単語の意味的な関係性の可視化
「king man + woman = queen」のような単語間の関係を2次元や3次元のベクトル空間上にプロットして可視化できます。類似した意味を持つ単語が近くに配置されることを確認できます。
出典:Word Embedding Analogies: Understanding King – Man + Woman = Queen | Kawin Ethayarajh
文書や文章の可視化
文書や文章をDoc2Vecでベクトル化し、次元圧縮して2次元にプロットすることで文書間の類似度を可視化。ニュース記事やレビューなどのテキストデータの可視化に活用できます。
作家の文体の比較
夏目漱石や芥川龍之介などの作家ごとにword2vecモデルを学習。単語の使われ方の違いから作家の文体を可視化して比較できます。
特許文書の可視化
特許文書をDoc2Vecでベクトル化し、次元削減して可視化。特許調査の効率化に役立てることができます。
商品のレコメンド
商品説明文をDoc2Vecでベクトル化。商品間の類似度を可視化してレコメンドに活用できます。
以上のように、word2vecやdoc2vecで単語や文書を分散表現にした後、次元圧縮手法と組み合わせて2次元や3次元にプロットすることで、テキストデータの関係性を視覚的に把握することができます。
自然言語処理の理解を深めたり、実務の課題解決に役立てたりするために、様々な分野で可視化が活用されています。