
LLMのベンチマーク
LLM(大規模言語モデル)の性能を評価するためのベンチマークには、以下のようなものがあります。
人間による評価
人間が生成された文章やタスクの出力を直接評価する最も信頼できる方法ですが、コストがかかります。
他のLLMによる自動評価 (LLM-as-a-judge)
別のLLMをレビュアーとして訓練し、評価を自動化する手法です。人手評価に近い評価ができますが、LLMの偏りが影響する可能性があります。
タスク別のベンチマーク
- 自然言語処理タスク (GLUE, SuperGLUE, MMLU等)
- 質問応答 (SQuAD, NarrativeQA等)
- 要約 (CNNDM, XSum等)
- 翻訳 (WMT等)
- コード生成 (APPS, CodeXGLUE等)
特定のタスクに特化したベンチマークで、そのタスクの性能を評価できます。
多様性ベンチマーク
生成された出力の多様性や新規性を評価するベンチマーク(LAMBDA等)もあります。
言語別ベンチマーク
日本語(JGLUE, ELYZA-tasks-100等)、中国語、多言語対応などの言語別ベンチマークも開発されています。
このように様々なベンチマークが提案されており、用途に合わせて複数のベンチマークを組み合わせて使うことが一般的です。LLMの性能評価は現在も活発に研究が行われている分野です。
LLMのベンチマークの種類
AIのベンチマークには様々なものがあり、目的に応じて使い分ける必要があります。

MLPerfは、機械学習を稼働させたときのハードウェア性能を測るベンチマーク。画像分類、オブジェクト検出、自然言語処理など、さまざまなタスクがカバーされています。主要企業が参加しており、モデルの性能比較に適しています。

MMMUは、大学レベルの知識と推論を必要とするマルチモーダル課題で、AIの高度な認識と推論能力を評価します。教科書や試験問題から収集された質問で構成され、AGI(汎用人工知能)に向けた重要なベンチマークです。
HellaSwagは、日常的な常識推論を評価するベンチマークで、人間には簡単だが最先端のAIモデルでも難しいタスクが含まれています。
VQA: Visual Question Answering
VQAv2は、画像の内容に関する質問に答えるビジュアル質問応答タスクで、マルチモーダル理解能力を評価します。
LLMの日本語ベンチマークのランキング(Rakuda)
日本語特化のベンチマークもあります。
Rakuda は、日本のトピックに関する一連の自由形式の質問に日本語でどれだけうまく答えることができるかに基づく、日本語大言語モデルのランキングです。GPT-4による自動評価です。
このベンチマークで、LLMの日本語の生成能力の高さがある程度わかるんですね。
The Rakuda Ranking of Japanese AI
具体的にはどういう便tにマークなのでしょうか?
- 日本語の話題に関する40の質問に対して、各LLMが回答を生成します。
- GPT-4がそれらの回答の対を比較し、どちらが優れた回答かを判断します。
- GPT-4の判断に基づいて、ベイズ推定によりBradley-Terry強度が算出され、LLMの順位が決定されます。
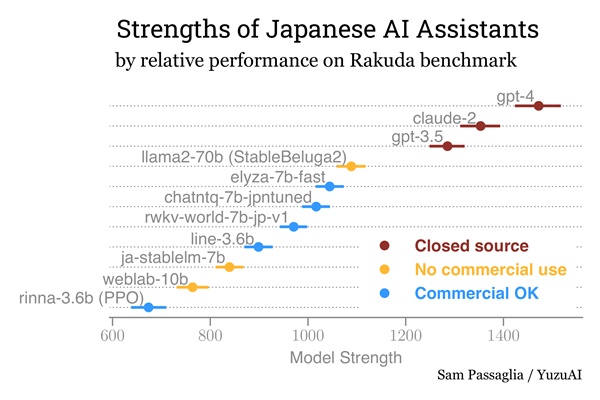
2024年4月24日時点のランキングは以下の通りです。
- gpt-4 (強度1472)
- claude-2 (強度1353)
- gpt-3.5 (強度1285)
- llama2-70b (StableBeluga2) (強度1089)
- elyza-7b-fast (強度1044)
… - 1weblab-10b (強度764)
強度の値が高いほど、そのLLMの日本語での質問回答能力が高いことを示しています。
ただし、ベンチマークの判定をGPT-4がおこなっているので、GPT-4有利という点は考慮したほうがいいかも知れませんね。
2023年10月に発表された商用LLM「LHTM-OPT」が、このベンチマークで最高スコアを記録しています。
なお、Rakudaの詳細な手法や、ソースコードはGitHubで公開されています。
LLMの性能って、最終的には「どれもあまり変わらない」というふうになってきそうなんですよね。
そこで選ぶ基準としては、「とにかく生成される日本語が自然」とか、そういう特化型になってきそう。
なので、Rakudaのような日本語に特化したベンチマークは貴重と考えます。
LLMのベンチマークのまとめ
- LLMには、性能を評価するためのベンチマークがあり、さまざまな評価方法があります。
- 日本語に対するベンチマーク(Rakuda)がネット上に公開され、更新されています。
- 自然言語処理、要約、翻訳、コード生成など目的別にベンチマーク方法が異なります。
関連 LLMと生成AIの違い